Cloud #1: utiliser Amazon S3 sans se ruiner
Amazon S3 on a tous entendu dire au moins une fois que c’est super, c’est pratique, et c’est facile à utiliser, et dans la théorie, c’est vrai, mais la mise en oeuvre peut être un peu plus complexe, surtout si on ne veut pas se ruiner. Pour mémoire, Amazon S3 c’est un peu comme un disque dur infini, où vous pouvez stocker tout type de fichier, de toute taille (ou presque), que vous pouvez ensuite servir directement via une url spécifique à chaque fichier. Vous pouvez donc y stocker vos images, vos vidéos, vos fichiers flash, vos docs, … Avec ce système, il n’est plus nécessaire de faire de backup, Amazon s’assurant de stocker de manière plus ou moins redondante les données selon la formule choisie.
Deux choses m’ont toujours freinées dans l’adoption de S3:
- la facturation du trafic qui fait rapidement grimper la facture (je sert actuellement environ 1To par mois d’images, qu’Amazon me facturerait donc à 0,15$/Go, soit quand même 150$/mois, face à 0E/mois quand je sert ces mêmes données depuis un serveur dédié low-cost en France). Imaginez maintenant que vous ayez un site populaire avec des contenus flash (par exemple un site de jeux), votre facture va surement être de plusieurs milliers de dollars par mois.
- la difficulté pour sécuriser les fichiers, afin d’éviter que n’importe qui fasse du hot-linking et que vous vous retrouviez à payer de la BP pour d’autres sites web, ce qui peut encore faire grimper la facture.
J’ai donc creusé le sujet et suite aux évolutions récentes d’Amazon S3 j’ai finalement franchi le pas en mettant en place un système de miroir via Nginx.
h2. Stocker
Il faut d’abord déplacer tous les fichiers existants vers Amazon S3: de nombreuses librairies et outils permettent de le faire, comme je développe en Rails, je suis passé par Paperclip. La structure des mes images est toujours la même: je conserve l’image dans sa taille d’origine, puis je réalise des déclinaisons en fonction des tailles que je vais utilisé dans les différentes pages de mon site. Si jamais ces tailles changent dans le futur, je peux donc toujours repartir de l’original pour refaire les vignettes adéquates. Du coup, j’ai choisi de stocker les images de 2 manières sur Amazon:
- les images originales sont stockées dans l’espace de stockage “classique” d’Amazon, au tarif de $0.14$/Go mois, et Amazon me garanti un taux de perte inférieur à 0.000000001% par an (autrement dit, s’ils me perdent un fichier, c’est que vraiment, j’ai pas de bol)
- les vignettes dérivées des originaux sont par contre stockées en choisissant l’option “Reduced Redundancy Storage”, qui apporte moins de garanties sur les pertes de données (taux de perte inférieur à 0,01% par an), mais qui permet de réduire la facture de 33% (le Go mensuel de stockage est facturé à $0.093$). Lorsque vous utilisez cette option de stockage, Amazon peut vous notifier automatiquement par mail ou sur une url spécifique de toute perte de fichier via leur système Amazon SNS, ce qui vous permet de réagir en relançant par exemple automatiquement la génération des vignettes perdues.
Pour ceux qui développent en Ruby avec Paperclip, voici 2 astuces parce que j’ai un peu ramer pour trouver les infos:
- Pour pouvoir utiliser le stockage S3 dans la zone Europe, il faut changer le host par défaut utilisé par Paperclip sinon cela ne fonctionne pas. Il suffit d’ajouter l’instruction suivante dans votre code :
AWS::S3::DEFAULT_HOST.replace "s3-eu-west-1.amazonaws.com"- Pour pouvoir mixer stockage normal et stockage “Reduced” dans Paperclip en fonction des vignettes, j’ai été obligé de faire ma propre classe de stockage ReducedS3.
h2. Délivrer
 Plutôt que de servir les images directement depuis Amazon, je continue de passer par Nginx sur l’un de mes serveurs, configuré pour fabriquer un miroir à la volée. Tout commence par la sécurisation des fichiers chez Amazon: depuis peu, il est possible de définir des règles d’accès global, au niveau de la racine de stockage de vos fichiers (ie, le “bucket”). Vous pouvez ainsi autoriser l’accès à vos fichiers uniquement à certaines IP, à certains user-agent (et en utilisant un User-agent compliqué avec une chaine de caractère unique que vous seul connaissez, cela revient à mettre un mot de passe global sur l’accès à vos fichiers), etc… Toutes les possibilités sont détaillées dans la doc sur les buckets policies.
Plutôt que de servir les images directement depuis Amazon, je continue de passer par Nginx sur l’un de mes serveurs, configuré pour fabriquer un miroir à la volée. Tout commence par la sécurisation des fichiers chez Amazon: depuis peu, il est possible de définir des règles d’accès global, au niveau de la racine de stockage de vos fichiers (ie, le “bucket”). Vous pouvez ainsi autoriser l’accès à vos fichiers uniquement à certaines IP, à certains user-agent (et en utilisant un User-agent compliqué avec une chaine de caractère unique que vous seul connaissez, cela revient à mettre un mot de passe global sur l’accès à vos fichiers), etc… Toutes les possibilités sont détaillées dans la doc sur les buckets policies.
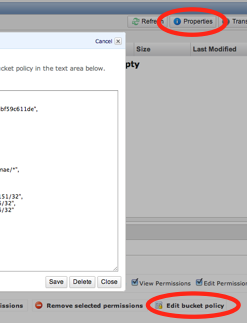
J’ai fais une restriction par IP pour le moment, car c’était le plus rapide à mettre en place pour moi. Il suffit d’afficher les propriété de votre “bucket” dans la console d’Amazon et tout en bas de l’onglet “Properties”, de cliquer sur “Add bucket policy” et copier le code suivant, en l’adaptant avec vos propres IP et votre nom de bucket (cf capture d’écran).
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "IPDeny",
"Effect": "Deny",
"Principal": {
"AWS": "*"
},
"Action": "s3:*",
"Resource": "arn:aws:s3:::BUCKET_NAME/*",
"Condition": {
"NotIpAddress": {
"aws:SourceIp": [
"192.168.1.1/32",
"192.168.1.2/32",
"192.168.1.3/32"
]
}
}
}
]
}
Une fois que c’est mis en place, il ne reste plus qu’à configurer le miroir nginx, dont le fonctionnement est le suivant:
- soit nginx trouve le fichier à servir sur le disque, et il le délivre au navigateur
- soit nginx ne le trouve pas et alors il le demande à Amazon, le stocke sur le disque du serveur, puis sert le fichier au navigateur.
Si vous n’avez jamais configuré nginx, je vous renvoie vers le guide d’installation de Nginx de Papygeek qui est bien fait. Pour la partie miroir vous trouverez un exemple de configuration tel qu’il est déployé actuellement sur mon site de Replay TV.
Ce système est idéal car:
- Contrairement aux caches classiques, les données persistent sur votre disque tant que vous n’effacez rien. De plus, la structure des fichiers sur le disque reproduit à l’identique votre arborescence chez S3 ce qui facilite la gestion du miroir, notamment pour expirer facilement un fichier.
- vous n’êtes facturé qu’une seule fois en terme de trafic: lors du téléchargement pour la première fois du fichier depuis Amazon pour le stocker localement
- vous pouvez mettre le miroir n’importe où, et pas forcement sur le même serveur que votre serveur applicatif, pour optimiser les performances. Un simple serveur à 15E/mois chez OVH bien configuré va vous permettre d’encaisser un gros trafic avec ce système, si vous dédiez ce serveur à cet usage unique.
h2. Evoluer
Si vous avez regardé l’exemple de configuration nginx que je vous ai mis, vous constaterez que toutes les images sont servies depuis les sous-domaines teleX.zeworld.com (X allant de 1 à 4), qui pointent en fait actuellement tous sur la même machine. Cela présente plusieurs avantages:
- cela me permet d’utiliser des domaines sans cookies (ie cookie-less domains), afin d’améliorer de quelques millisecondes chaque échange entre le navigateur et le serveur, en évitant la transmission de cookies par le navigateur, qui ne servent à rien pour délivrer du contenu statique.
- cela me permet de contourner la limitation des navigateurs qui n’établissent jamais plus de 2 à 4 connexions simultanées sur une même nom de machine, et donc me permet de délivrer très rapidement des pages y compris celles avec de nombreuses images.
- si jamais le serveur ne tient plus la charge, il me suffit d’ajouter une nouvelle machine, de configurer nginx à l’identique, et de modifier les DNS en conséquence pour démultiplier la capacité à servir les contenu statiques. C’est très rapide, puisque il n’y pas de données à copier, le miroir sur chaque nouveau serveur va se créer tout seul au fil de l’eau.
Autre piste d’évolution, si vous avez des contenus extrêmement populaires et consultés en permanence, une bonne idée est de rajouter un cache Varnish devant Nginx pour servir ces contenus directement depuis la mémoire du serveur, pour gagner encore plus en performance. Je n’ai pas ce type de besoin pour le moment donc je n’ai pas creusé plus en détail.
Enfin, si vraiment vous vous apprêtez à faire face à un pic de trafic extrêmement important mais sur une très courte période (par exemple dans le cadre d’une opération événementielle), alors le mieux reste tout de même de servir directement vos fichiers depuis Amazon S3: c’est simple et plus économique que de passer du temps à configurer plusieurs serveurs pour ensuite les déprovisionner.
h2. Conclusion
Avec ce système mis en place, je n’ai plus besoin de me soucier des backups (avant je devais trouver le moyen de préserver correctement et rapidement 100Go de fichiers, c’était un peu lourd à gérer). Il me reste encore à automatiser le traitement des notifications d’Amazon en cas de perte d’un fichier, mais je vais attendre que cela se produise pour m’y coller ;-) En terme de coût, cela me revient donc à environ 15$/mois de stockage + quelques dollars de trafic + le cout du serveur hébergeant nginx. Alors bien sur cela coute un peu plus cher que si je continuais à tout faire à l’arrache comme jusqu’à présent, mais ce n’est vraiment pas cher pour être serein ;-)
Alors bien sur, il existe plein d’autres fournisseurs qui proposent la même chose qu’Amazon pour faire du stockage, et parfois moins cher, mais l’avantage d’Amazon, c’est qu’il existe un très grand nombre de librairies ce qui simplifie énormément la mise en oeuvre. Cependant ce schéma peut être reproduit à priori avec n’importe quel fournisseur de stockage qui vous facture la BP.
Enfin, depuis le 1er novembre, Amazon vous permet d’utiliser tout un tas de choses gratuitement pendant 1 an. Par exemple, pour Amazon S3, vous bénéficiez de 5 Go de stockage et de 15Go de transfert vers internet gratuit par mois: un bon moyen pour vous motiver à faire les choses bien dès maintenant.
Je suis à votre disposition pour toute précision, et j’attend vos remarques et vos suggestions dans les commentaires, faites comme chez vous, on est entre amis ;-)
Cet article fait parti d’une série d’articles sur des cas concrets d’utilisation du cloud.